

Moving from hype to practice is an important but challenging step for ICT4D practitioners. As the technical adviser for digital development at IREX, a global development and education organization, I’ve been watching with cautious optimism as international development stakeholders begin to explore how artificial intelligence tools like machine learning can help them address problems and introduce efficiencies to amplify their impact.
Working on ML? Share your experience at Tech Salon DC!
So while USAID was developing their guide to making machine learning work for international development and TechChange rolled out their new course on Artificial Intelligence for International Development, we spent a few months this summer exploring whether we could put machine learning to work to measure media quality.
Of course, we didn’t turn to machine learning just for the sake of contributing to the “breathless commentary of ML proponents” (as USAID aptly puts it).
As we shared in a session with our artificial intelligence partner Lore at MERLTech DC 2018, some of our programs face a very real set of problems that could be alleviated through smarter use of digital tools.
Our Machine Learning Experiment
In our USAID-funded Media Strengthening Program in Mozambique, for example, a small team of human evaluators manually score thousands of news articles based on 18 measures of media quality.
This process is time consuming (some evaluators spend up to four hours a day reading and evaluating articles), inefficient (when staff turns over, we need to reinvest resources to train up new hires), and inconsistent (even well-trained evaluators might score articles differently).
To test whether we can make the process of measuring media quality less resource-intensive, we spent a few months training software to automatically detect one of these 18 measures of media quality: whether journalists keep their own opinions out of their news articles. The results of this experiment are very compelling:
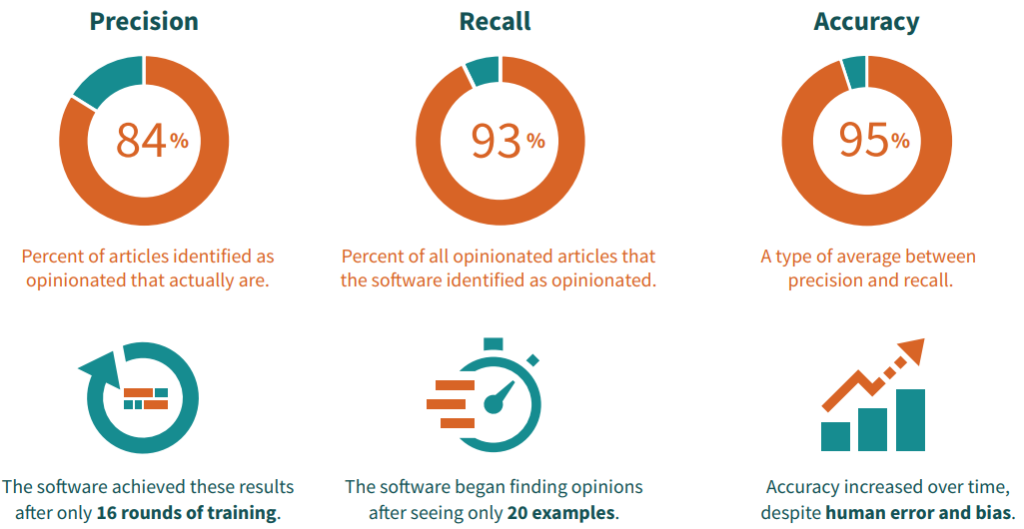
- The software had 95% accuracy in recognizing sentences containing opinions within the dataset of 1,200 articles.
- The software’s ability to “learn” was evident. Anecdotally, the evaluation team noticed a marked improvement in the accuracy of the software’s suggestions after showing it only twenty sentences that had opinions. The accuracy, precision, and recall results highlighted above were achieved after only sixteen rounds of training the software.
- Accuracy and precision increased the more that the model was trained. There is a clear relationship between the number of times the evaluators trained the software and the accuracy and precision of the results. The recall results did not improve over time as consistently.
These results, although promising, simplify some numbers and calculations. Check out our full report for details.
What does this all mean? Let’s start with the good news. The results suggest that some parts of media quality—specifically, whether an article is impartial or whether it echoes its author’s opinions—can be automatically measured by machine learning.
The software also introduces the possibility of unprecedented scale, scanning thousands of articles in seconds for this specific indicator. These implications introduce ways for media support programs to spend their limited resources more efficiently.
3 Lessons Learned from using Machine Learning
Of course, the machine learning experience was not without problems. With any cutting-edge technology, there will be lessons we can learn and share to improve everyone’s experience. Here are our three lessons learned working with machine learning:
1. Forget about being tech-literate; we need to be more problem-literate.
Defining a coherent, specific, actionable problem statement was one of the important steps of this experiment. This wasn’t easy. Hard trade-offs had to be made (Which of 18 indicators should we focus on?), and we had to focus on things we could measure in order to demonstrate efficiency games using this new approach (How much time do evaluators currently spend scoring articles?).
When planning your own machine learning project, devote plenty of time at the outset—together with your technology partner—to define the specific problem you’ll try to address. These conversations result in a deeper shared understanding of both the sector and the technology that will make the experiment more successful.
2. Take the time to communicate results effectively.
Since completing the experiment, people have asked me to explain how “accurate” the software is. But in practice, machine learning software uses different methods to define “accuracy”, which in turn can vary according to the specific model (the software we used deploys several models).
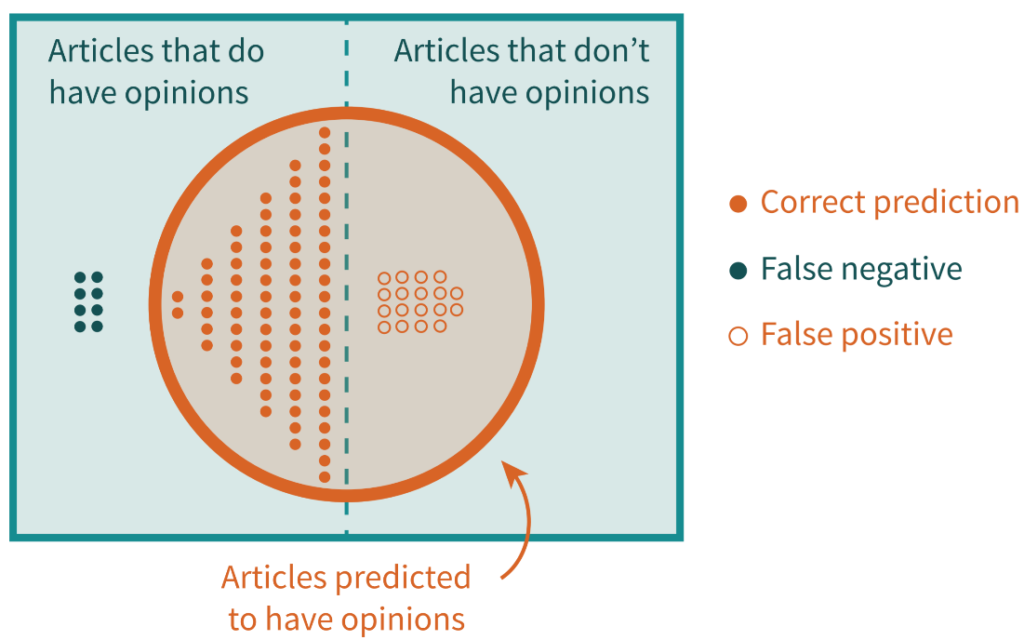
What starts off as a simple question (How accurate is our software?) can easily turn into a discussion of related concepts like precision, recall, false positives, and false negatives. We found that producing clean visuals (like this or this) became the most effective way to explain our results.
3. Start small and manage expectations.
Stakeholders with even a passing awareness of machine learning will be aware of its hype. Even now, some colleagues ask me how we “automated the entire media quality assessment process”—even though we only used machine learning to identify one of 18 indicators of media quality. To help mitigate inflated expectations, we invested a small amount into this “minimum viable product” (MVP) to prove the fundamental concept before expanding on it later.
Approaching your first machine learning project this way might help to keep expectations in line with reality, minimize risks associated with experimentation, and provide air cover for you to adjust your scope as you discover limitations or adjacent opportunities during the process.
Samhir Vasdev is the Technical Adviser for Digital Development at IREX’s Center for Applied Learning and Impact.

{kind=link}
{kind=link}
I am interested to hear what specific tool you used. Was this a custom solution or did you use one of the many sentiment analysis tools available? Curious about the scalability and cost effectiveness of custom vs off the shelf solutions.
Thanks Peter for the questions. We definitely considered applying existing sentiment analysis tools for this problem, in keeping with our commitment to the Digital Principles. But the problem (finding opinions, in Portuguese) was a bit more nuanced than what we thought sentiment analysis could offer (but we could be wrong!). We also realized that we needed a bit more help in actually applying the tools (i.e. technical assistance), so we were looking for a partner who has experience doing that who can play a consulting role as well. In the end, we used an off-the-shelf (but not open-source) tool and services provided by by Lore AI. Keeping in mind we have limited in-house tech capacity, and basically no internal machine learning capacity so would have anyways needed to build that up, I think this was a cost effective approach, but could definitely be wrong. Are there any examples out there using existing sentiment analysis tools that address a problem statement similar to ours? Would love to learn from you!
AI , machine lauguage is the future. We actually don’t need to work, we can get our selves representatives and the just enjoy vacation for life
Fascinating project—a clear way that we can reap benefits from machine learning without the hype. I recently attended a talk by Virginia Eubanks, author of Automating Inequality: How High-Tech Tools Profile, Police and Punish the Poor, and her investigation of algorithms in US public benefits systems pointed out the ways that current inequalities can get incorporated into process automation, particularly when there is no opportunity for an “empathy override” by a human. The risk of this happening in your algorithms could be tested by comparing it to the results of a highly diverse and socially aware control group of evaluators. I am curious what biases, if any, could be introduced in this type of project—for example, whether the algorithm is overly harsh on articles written by non-native speakers compared to a more empathetic human evaluator. What are the next steps for the technology (ie. is it being implemented in Mozambique)?
Thanks Katie for the kind feedback and remarks. The risks of embedding human biases into algorithms is all-too-real. Cathy O’Neill’s recent book, Weapons of Math Destruction, underscores the dangers. I am sure there are several biases we ingrained into the algorithms that were detecting stories that contained opinions when they shouldn’t. For instance, the very definition of what counts as an “opinion” requires some subjective decision making (i.e. bias). An I’m sure articles written by non-native Portuguese speakers might also not be detected as accurately by the ML software (although this is a very conscious bias; this software was deliberately trained only on native / proficient Portuguese articles.
Now that we have this proof of concept, we have some ideal next steps and hope to partner with funders who share our interest to continue evolving this experiment and scaling it in other contexts.